提交
This commit is contained in:
parent
747d95a05f
commit
40797fd3c8
95
source/_posts/Docker-Compose.md
Normal file
95
source/_posts/Docker-Compose.md
Normal file
@ -0,0 +1,95 @@
|
|||||||
|
---
|
||||||
|
title: Docker-Compose
|
||||||
|
date: 2024-04-01 11:02:56
|
||||||
|
tags:
|
||||||
|
---
|
||||||
|
|
||||||
|
# 集群搭建
|
||||||
|
|
||||||
|
## Flink 集群
|
||||||
|
|
||||||
|
1. 首先启动flink 容器 JobManager、TaskManager 两个容器将配置文件复制出来方便挂载
|
||||||
|
```shell
|
||||||
|
docker run \
|
||||||
|
-itd \
|
||||||
|
--name=jobmanager \
|
||||||
|
--publish 8081:8081 \
|
||||||
|
--network flink-network \
|
||||||
|
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
|
||||||
|
flink:scala_2.12-java8 jobmanager
|
||||||
|
|
||||||
|
docker run \
|
||||||
|
-itd \
|
||||||
|
--name=taskmanager \
|
||||||
|
--network flink-network \
|
||||||
|
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
|
||||||
|
flink:scala_2.12-java8 taskmanager
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
2. 创建本地卷挂载目录,拷贝文件
|
||||||
|
```shell
|
||||||
|
mkdir -p /usr/local/flink-docker/jobmanager
|
||||||
|
mkdir -p /usr/local/flink-docker/taskmanager
|
||||||
|
docker cp jobmanager:/opt/flink/lib /usr/local/flink-docker/jobmanager
|
||||||
|
docker cp jobmanager:/opt/flink/log /usr/local/flink-docker/jobmanager
|
||||||
|
docker cp jobmanager:/opt/flink/conf /usr/local/flink-docker/jobmanager
|
||||||
|
|
||||||
|
docker cp taskmanager:/opt/flink/lib /usr/local/flink-docker/taskmanager
|
||||||
|
docker cp taskmanager:/opt/flink/log /usr/local/flink-docker/taskmanager
|
||||||
|
docker cp taskmanager:/opt/flink/conf /usr/local/flink-docker/taskmanager
|
||||||
|
```
|
||||||
|
|
||||||
|
3. 搭建集群
|
||||||
|
```yaml
|
||||||
|
version: "2.2"
|
||||||
|
services:
|
||||||
|
jobmanager:
|
||||||
|
image: flink:scala_2.12-java8
|
||||||
|
container_name: jobmanager-1
|
||||||
|
expose:
|
||||||
|
- "6123"
|
||||||
|
ports:
|
||||||
|
- "8081:8081"
|
||||||
|
command: jobmanager
|
||||||
|
volumes:
|
||||||
|
- /usr/local/flink-docker/jobmanager/conf:/opt/flink/conf
|
||||||
|
- /usr/local/flink-docker/jobmanager/lib:/opt/flink/lib
|
||||||
|
- /usr/local/flink-docker/jobmanager/log:/opt/flink/log
|
||||||
|
environment:
|
||||||
|
- |
|
||||||
|
FLINK_PROPERTIES=
|
||||||
|
jobmanager.rpc.address: jobmanager
|
||||||
|
parallelism.default: 2
|
||||||
|
#web.upload.dir: /opt/flink/target
|
||||||
|
networks:
|
||||||
|
- flink-network
|
||||||
|
taskmanager:
|
||||||
|
image: flink:scala_2.12-java8
|
||||||
|
container_name: taskmanager-1
|
||||||
|
depends_on:
|
||||||
|
- jobmanager
|
||||||
|
command: taskmanager
|
||||||
|
scale: 1
|
||||||
|
volumes:
|
||||||
|
- /usr/local/flink-docker/taskmanager/conf:/opt/flink/conf
|
||||||
|
- /usr/local/flink-docker/taskmanager/lib:/opt/flink/lib
|
||||||
|
- /usr/local/flink-docker/taskmanager/log:/opt/flink/log
|
||||||
|
environment:
|
||||||
|
- |
|
||||||
|
FLINK_PROPERTIES=
|
||||||
|
jobmanager.rpc.address: jobmanager
|
||||||
|
taskmanager.numberOfTaskSlots: 2
|
||||||
|
parallelism.default: 2
|
||||||
|
networks:
|
||||||
|
- flink-network
|
||||||
|
networks:
|
||||||
|
flink-network:
|
||||||
|
external: true
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -474,6 +474,67 @@ ADD 指令和 COPY 的使用格类似(同样需求下,官方推荐使用 COP
|
|||||||
|
|
||||||
- ADD 的优点
|
- ADD 的优点
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### networks
|
||||||
|
|
||||||
|
#### 使用已经存在的网络
|
||||||
|
|
||||||
|
```shell
|
||||||
|
docker network create flink-network
|
||||||
|
```
|
||||||
|
|
||||||
|
```yaml
|
||||||
|
version: "2.2"
|
||||||
|
services:
|
||||||
|
jobmanager:
|
||||||
|
image: flink:scala_2.12-java8
|
||||||
|
container_name: jobmanager-1
|
||||||
|
expose:
|
||||||
|
- "6123"
|
||||||
|
ports:
|
||||||
|
- "8081:8081"
|
||||||
|
command: jobmanager
|
||||||
|
volumes:
|
||||||
|
- /usr/local/flink-docker/jobmanager/conf:/opt/flink/conf
|
||||||
|
- /usr/local/flink-docker/jobmanager/lib:/opt/flink/lib
|
||||||
|
- /usr/local/flink-docker/jobmanager/log:/opt/flink/log
|
||||||
|
environment:
|
||||||
|
- |
|
||||||
|
FLINK_PROPERTIES=
|
||||||
|
jobmanager.rpc.address: jobmanager
|
||||||
|
parallelism.default: 2
|
||||||
|
web.upload.dir: /opt/flink/target
|
||||||
|
networks:
|
||||||
|
- flink-network
|
||||||
|
taskmanager:
|
||||||
|
image: flink:scala_2.12-java8
|
||||||
|
container_name: taskmanager-1
|
||||||
|
depends_on:
|
||||||
|
- jobmanager
|
||||||
|
command: taskmanager
|
||||||
|
scale: 1
|
||||||
|
volumes:
|
||||||
|
- /usr/local/flink-docker/taskmanager/conf:/opt/flink/conf
|
||||||
|
- /usr/local/flink-docker/taskmanager/lib:/opt/flink/lib
|
||||||
|
- /usr/local/flink-docker/taskmanager/log:/opt/flink/log
|
||||||
|
environment:
|
||||||
|
- |
|
||||||
|
FLINK_PROPERTIES=
|
||||||
|
jobmanager.rpc.address: jobmanager
|
||||||
|
taskmanager.numberOfTaskSlots: 2
|
||||||
|
parallelism.default: 2
|
||||||
|
networks:
|
||||||
|
- flink-network
|
||||||
|
networks:
|
||||||
|
flink-network:
|
||||||
|
external: true
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# Docker 实例
|
# Docker 实例
|
||||||
|
|
||||||
## Docker 启动 MariaDB
|
## Docker 启动 MariaDB
|
||||||
|
|||||||
60
source/_posts/Flink.md
Normal file
60
source/_posts/Flink.md
Normal file
@ -0,0 +1,60 @@
|
|||||||
|
---
|
||||||
|
title: Flink
|
||||||
|
date: 2024-04-02 14:39:41
|
||||||
|
tags:
|
||||||
|
---
|
||||||
|
|
||||||
|
## 流处理
|
||||||
|
|
||||||
|
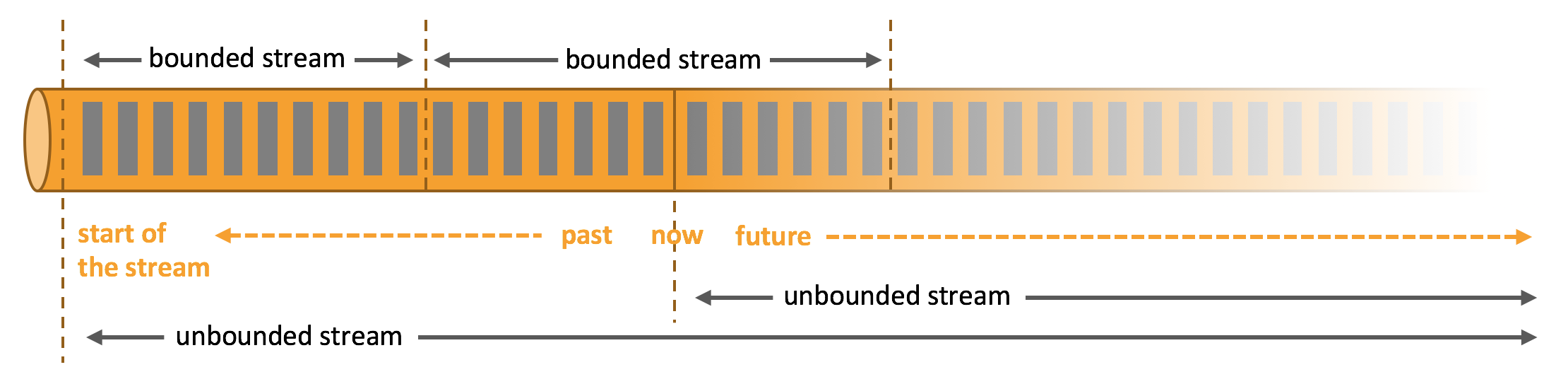
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 *有界流*(*bounded*)或 *无界流*(*unbounded*)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**批处理**是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
|
||||||
|
|
||||||
|
**流处理**正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
|
||||||
|
|
||||||
|
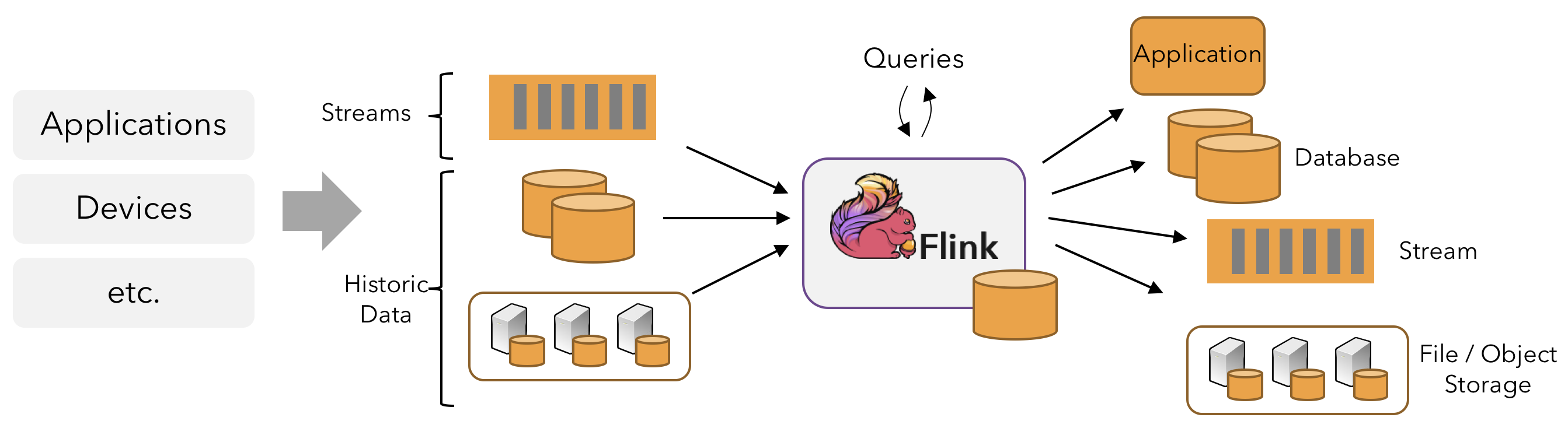
在 Flink 中,应用程序由用户自定义**算子**转换而来的**流式 dataflows** 所组成。这些流式 dataflows 形成了有向图,以一个或多个**源**(source)开始,并以一个或多个**汇**(sink)结束。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
通常,程序代码中的 transformation 和 dataflow 中的算子(operator)之间是一一对应的。但有时也会出现一个 transformation 包含多个算子的情况,如上图所示。
|
||||||
|
|
||||||
|
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# DataStream API介绍和示例
|
||||||
|
|
||||||
|
#### Flink程序运行流程
|
||||||
|
|
||||||
|
###### 1. 获取执行环境
|
||||||
|
|
||||||
|
> getExecutionEnvironment()
|
||||||
|
> createLocalEnvironment()
|
||||||
|
> createRemoteEnvironment(String host, int port, String... jarFiles)
|
||||||
|
|
||||||
|
###### 2. 加载创建初始化数据
|
||||||
|
|
||||||
|
> readTextFile()
|
||||||
|
> addSource
|
||||||
|
> ..
|
||||||
|
|
||||||
|
###### 3. 对数据在transformation operator
|
||||||
|
|
||||||
|
> map
|
||||||
|
> flatMap
|
||||||
|
> filter
|
||||||
|
> ..
|
||||||
|
|
||||||
|
###### 4. 指定计算结果的输出位置 sink
|
||||||
|
|
||||||
|
> print()
|
||||||
|
> writeAdText(String path)
|
||||||
|
> addSink
|
||||||
|
> ..
|
||||||
|
|
||||||
|
###### 5. 触发程序执行 execute
|
||||||
|
|
||||||
|
> env.execute()
|
||||||
|
> 在sink是print时,不需要显示execute,否则会报错。因为在print方法里已经默认调用了execute。
|
||||||
@ -650,3 +650,24 @@ volatile虽然**具备可见性**,但是**不具备原子性**。
|
|||||||
5. **Lock**可以提高多个线程进行读操作的效率(读写锁)。
|
5. **Lock**可以提高多个线程进行读操作的效率(读写锁)。
|
||||||
|
|
||||||
**在性能上来说**,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时**Lock**的性能要远远优于**synchronized**。所以说,在具体使用时要根据适当情况选择。
|
**在性能上来说**,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时**Lock**的性能要远远优于**synchronized**。所以说,在具体使用时要根据适当情况选择。
|
||||||
|
|
||||||
|
## 匿名内部类
|
||||||
|
|
||||||
|
匿名内部类是一种特殊的类定义方式,它没有明确的类名,且在定义的同时就实例化了这个类的对象。在Java中,匿名内部类常常用于简化只使用一次的类的创建过程,尤其是在只需要实现单个接口或继承单一父类的情况下。
|
||||||
|
|
||||||
|
```java
|
||||||
|
streamSource.keyBy(new KeySelector<String, String>() {
|
||||||
|
@Override
|
||||||
|
public String getKey(String s) throws Exception {
|
||||||
|
int i = Integer.parseInt(s);
|
||||||
|
return i > 500 ? "ge" : "lt";
|
||||||
|
}
|
||||||
|
})
|
||||||
|
```
|
||||||
|
|
||||||
|
这里的 new KeySelector<String, String>() {...} 就是一个匿名内部类的实例。具体来说:
|
||||||
|
|
||||||
|
- KeySelector 是一个接口(或抽象类)。
|
||||||
|
- 匿名内部类实现了 KeySelector 接口,并重写了其中的 getKey 方法。
|
||||||
|
- 因为并没有给这个类命名,所以在创建对象时直接定义其实现细节,而不需要先定义一个单独的类。
|
||||||
|
- 这个匿名内部类实例随后作为参数传递给 streamSource.keyBy(...) 方法,说明了它是根据运行时需求即时创建并使用的。
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user